Теория вероятности и немного магии: как увеличить продажи при помощи математики

Нумерофобия — это боязнь цифр и манипуляций с ними. Речь не о страхе, что у вас в шкафу прячется гигантская восьмёрка, а именно о ступоре перед любого рода подсчётами. Известно, что фобии лечатся продолжительным контактом с объектом страха. Поэтому, даже если вас и не вгоняют в панику уравнения с несколькими переменными, считать иногда нужно хотя бы для профилактики. А ещё для того, чтобы увеличить продажи.
Однажды мы увеличили федеральному телеком-оператору конверсию в заявку на 30%. Об этом уже есть подробный кейс, а сейчас — продолжение истории.
Стало понятно, что мы достигли максимума по заявкам, и пришло время ставить новые задачи. Сформулировали их так:
- уменьшить количество показов поп-апов без потери объёма лидов;
- уменьшить количество некачественных заявок без потери количества подключений.
Амбициозно, не так ли? Начали думать, как реализовать идею, и поняли, что потребуется немножко магии. Вот было бы здорово уметь предсказывать, какой пользователь оставит заявку и какой оформит договор! Тогда бы мы показывали поп-апы только нужным пользователям в нужный момент.
Мечта оказалась осуществима при помощи машинного обучения. Мы применили модель байесовского классификатора — одну из важнейших в теории вероятности. Обо всём по порядку.
Немного теории
Разбираться в теории вероятности — сложно. Чтобы разложить всё по полочкам, можно представить простой пример. Очень хорошо это получилось в одном из тредов на Stack Overflow.
Классификатор Байеса считается следующим образом:

A — событие или класс, а параметры — это свойства, по которым это событие или класс можно определить. Параметров может быть сколько угодно.
Чаще всего в исследовании используют набор параметров, предполагая, что они не зависят друг от друга. Классификатор называют наивным, поскольку обычно так не бывает: признаки одного предмета так или иначе связаны между собой.
Итак, представим, что у нас есть 1000 фруктов: 500 бананов, 300 апельсинов и 200 каких-нибудь ещё (это классы). Введём три определения: длинный, сладкий и жёлтый (это параметры). Занесём данные в табличку:
| Класс | Длинный | Сладкий | Жёлтый | Всего |
| Банан | 400 | 350 | 450 | 500 |
| Апельсин | 0 | 150 | 300 | 300 |
| Другой | 100 | 150 | 50 | 200 |
| Всего | 500 | 650 | 800 | 1000 |
Из общей корзины взяли один случайный фрукт. Наша задача — определить его, если мы знаем его параметры: он длинный, сладкий и жёлтый.
Сперва нужно посчитать вероятность того, что неизвестный фрукт — это банан. Получается, что нам необходимо вычислить P (банан I длинный, сладкий, жёлтый).
Считаем вероятности присутствия каждого параметра в классе:
P (длинный I банан) = 400/500 = 0.8
P (сладкий I банан) = 350/500 = 0.7
P (жёлтый I банан) = 450/500 = 0.9
P (банан) = 500/1000 = 0.5
Теперь, согласно уравнению, нам нужно перемножить все эти значения:
P (банан I длинный, сладкий, жёлтый) = 0.8 * 0.7 * 0.9 * 0.5 = 0.252
Поскольку нам предстоит сравнить вероятности трёх классов по одинаковым параметрам, то знаменатель в уравнении для каждого класса тоже будет одинаковым, его можно не считать.
Нужно проделать то же самое для других классов: апельсины и другие фрукты. Не будем мучить вас вычислениями: P (апельсин I длинный, сладкий, жёлтый) = 0, P (другой I длинный, сладкий, жёлтый) = 0.01875
Теперь наша задача сравнить полученные вероятности. Самый большой показатель — 0.252, то есть, согласно наивному байесовскому классификатору, взятый нами случайно длинный, сладкий и жёлтый фрукт — это банан.
Формула достаточно простая, но полезная. С её помощью можно определить предмет по его признакам, а сами вычисления несложно автоматизировать.
Реализация
Вернёмся к нашим задачам. Для их решения не обойтись без машинного обучения. Однако, есть техническая особенность: речь идёт о сайте с полумиллионным трафиком, и желательно реализовать механизм без затрат на серверные мощности. Ещё важно помнить о скорости, иначе, пока модель будет предсказывать намерения пользователя, он может уже попросту покинуть сайт.
Наивный байесовский классификатор оказался самым простым и эффективным решением.
Мы выделили ряд признаков, например, некоторые utm-метки или свойства пользователя, по которым можно определить его поведение. Простой пример: если человек провёл достаточно много времени на странице телефонии, открывал разделы и читал подробные условия каждого тарифа, вероятно, он заинтересован. Мы можем предложить ему консультацию именно по этому разделу.
Далее определили два класса: клиенты, готовые заключить договор, и клиенты, которые вероятнее всего уйдут в отток. Обозначили параметры, по которым можно определить принадлежность к первому или второму классу, и начали действовать. Выгрузили данные по признакам пользователей и провели расчёты.
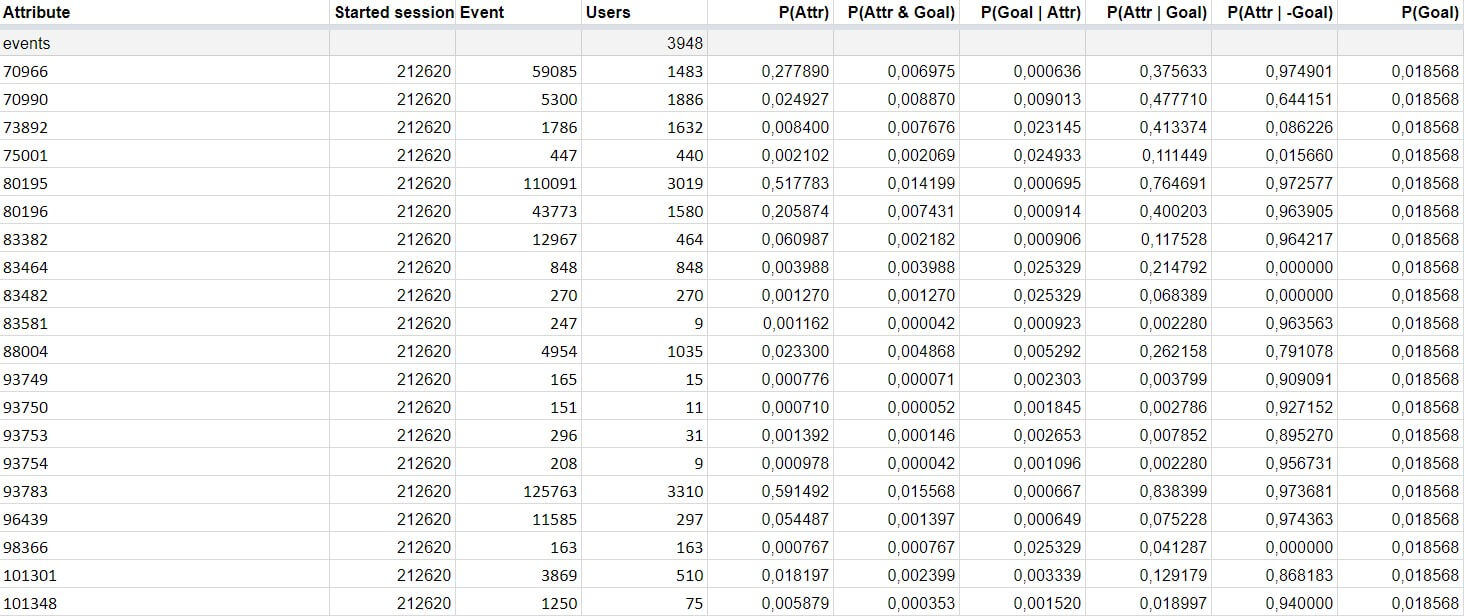
Пользователи, набравшие определённое количество баллов, видели поп-ап, в котором мы спрашивали их номер телефона для консультации. Тем, кто оказался не заинтересован, поп-ап не показывался.
Важно помнить, что сами по себе произведения вероятностей — это просто цифры. Суть в том, чтобы сравнивать их между собой (самое большое число — наиболее вероятный класс). В нашем случае 2 класса: те, кто готовы подключиться, и те, кто не готовы.
Модель предскажет, что пользователь готов, если он совершил какое-либо очевидное действие, связанное с заявкой. Чтобы «ловить» его раньше, нужно принимать во внимание только значительную разницу показателей.
Преимущества реализации наивного байесовского классификатора в том, что его легко написать на Javascript. Кроме того, операция производится прямо на компьютере пользователя в его браузере, нам не нужно тратить собственные ресурсы на реализацию.
Результат
Мы запустили сценарий в апреле и получили следующие результаты:
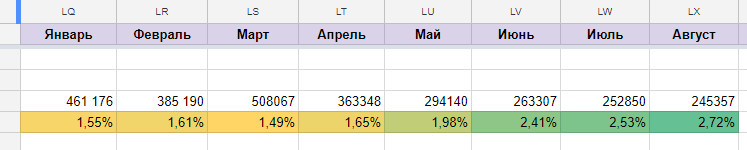
До внедрения машинного обучения конверсия в поп-ап была 1,49%, после — 2,53% без потери количества лидов. Это отличные показатели.
Зачем ещё нужен классификатор?
Формула помогла нам классифицировать пользователей, но это не всё, на что она способна. Её часто применяют для других, не менее важных дел.
- Фильтрация спама. Маркетологи боятся слова «спам», но чтобы никогда не сталкиваться с ним, нужно понимать, как устроен механизм фильтрации. Фильтр анализирует каждое слово в письме и присваивает ему вес — вероятность того, что текст с этим словом является спамом. Затем вычисляется вес письма — это средний вес всех его слов. В зависимости от установленной «весовой планки» фильтр принимает решение о дальнейшей судьбе письма (чем выше вес, тем больше вероятность, что письмо попадёт в спам).
- Прогнозирование продаж. Байесовский классификатор можно использовать для ответа на вопрос: «Какова вероятность, что поток клиентов увеличится, если сейчас март?». Вы оцениваете, как часто количество продаж росло в начале весны и были ли случаи, когда в это время оно падало, а затем сравниваете вероятности.
- Классификация текстов. Можно настроить механизм таким образом, чтобы он автоматически наполнял каталоги интернет-магазинов, определял язык текста, подбирал и показывал контекстную рекламу определённому сегменту, классифицировал документы и выполнял множество других полезных вещей, которые сделают вашу работу проще.
Машинное обучение — это здорово, не нужно бояться автоматизировать некоторые процессы. Например, понаблюдайте за поведением пользователей, попробуйте разделить их на группы, вы наверняка найдете несколько определяющих признаков для каждой. По этим же признакам вы сможете определить намерения пользователей, и в зависимости от этого строить коммуникацию. Вскоре вы увидите, что реклама стала работать эффективнее, база контактов значительно увеличилась и продажи возросли. Сначала может быть непросто, но мы рядом и с радостью вам поможем.







Подпишитесь на рассылку Carrot quest
1 письмо в неделю со свежими материалами о маркетинге, поддержке и продажах
Нажимая на кнопку, вы даете согласие на обработку персональных данных
Нажимая на кнопку, вы даете согласие на получение рекламно-информационных материалов
